【TVM-01】-整体设计理念
这是深度学习编译器的学习开篇,我打算从tvm这个开源的深度学习编译器开始,了解深度学习编译器的具体构造与源码分析,具体将采取自顶向下的探索思路进行学习。首先是TVM的整体设计理念,我们从陈天奇大佬的论文(TVM: An Automated End-to-End Optimizing Compiler for Deep Learning(OSDI 2018))开始tvm的学习。
摘要
TVM是一种深度学习编译器,它是一种硬件无关的编译器,可以支持各种硬件平台的部署,如GPU,PFGA与ASIC等。用于解决深度神经网络中算子融合,映射到具体硬件时原语编译以及memory latency hiding(不知道咋翻译)等优化问题。
背景介绍
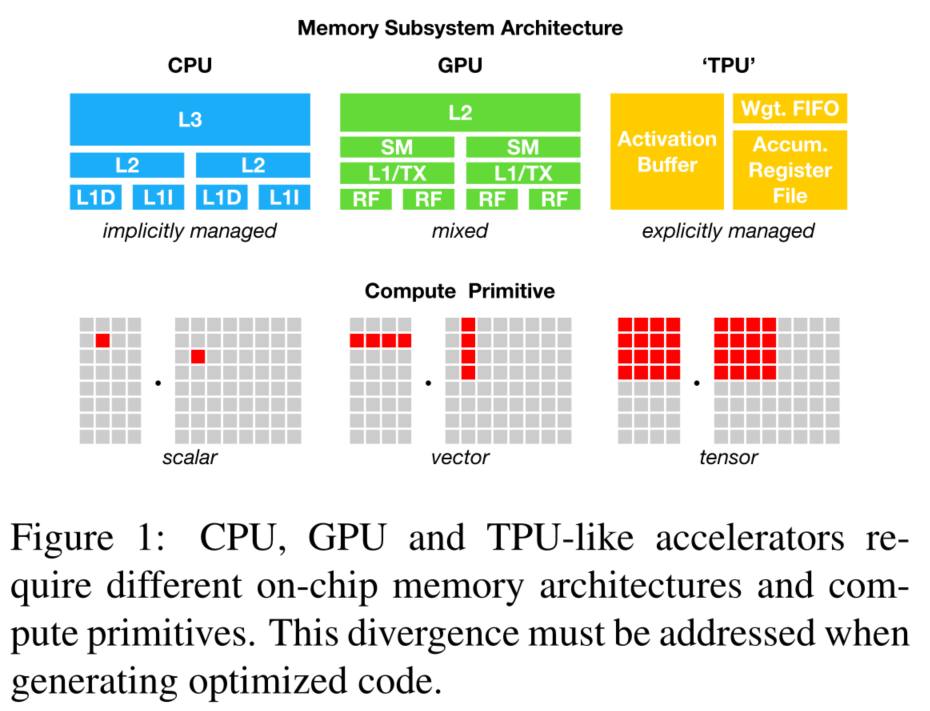
针对需要将神经网络部署到各种不同的硬件设备中,这种需求广泛存在与深度学习时代。不同的硬件设备其内存组织方式,单元计算函数等都不一样,如下图所示:
目前的深度学习框架如Tensoflow,pytorch,caffe等都依靠计算图中间表示来优化自动微分与动态内存管理等,这种基于图的优化过于high level,导致无法处理特定硬件的运算符转换,大部分的框架都集中优化一小类的服务器级的GPU,针对特定运算符的优化则交给一些GPU的运算符库。这种算子级的库一般需要大量的手动调优,但是绝大部分的算子库都并没有开源,所以无法轻松进行跨硬件的移植工作。而且即使对于已经支持的算子库,在应对新的算子的时候也会失效。
tvm旨在利用从各种深度学习框架得到高层的神经网络,并针对特定的设备进行低层优化。实现一个深度学习编译器具有如下两个困难
- 如何利用特定硬件的特性以及抽象:不同的硬件结构其输入的组织形式是不一样的,对于一个多维的张量,其数据的布局,以及在内存中的层次结构也可能各不相同。
- 优化搜索空间过大:内存访问,线程模式以及各种硬件原语的组合为生成的代码(如循环块,排序,缓存,展开)创建了巨大的配置空间,如果我们使用黑盒来自动调优,这将导致大量的搜索成本。
为解决上面两个挑战,tvm提出三个关键模块:
- 引入张量表达式语言来构建运算符并提供程序转换原语,这些原语可以生成具有各种优化的不同版本的程序。该层扩展了Halide的计算/调度分离概念,还将目标硬件内在函数与转换原语进行分离,从而支持新的加速器极其响应的内在函数。
- 引入自动程序优化框架来寻找优化的张量算子。该优化器通过一个基于机器学习的成本模型,从硬件后端收集数据来进行成本模型的适应和改进。
- 在自动代码生成器之上,我们引入一个图重写器,用于充分利用高层和算子层的优化。
TVM整体框架
TVM整体框架如下图所示,框架首先从现有深度学习框中输入一个模型,将其转换为计算图表达形式,然后执行数据流重写(如算子融合)来优化生成的计算图;在算子级优化中,算子优化模块需要为每个融合算子生成高效的执行代码,一般一个算子在张量表示语言中是特定的,但其具体执行细节并未指定,TVM为给定的硬件设备的算子一组可能的代码优化,然后使用成本模型来寻找优化的算子;最后TVM框架将生成的代码打包进一个可部署的模块之中,这样就完成了TVM的整个执行周期。